文章很多,相关文章也很多,用标签相互关联起来,有利于访问者也有利于seo,
靠纯手工应对操作,会很快崩溃!所以
用AI吧
第一步,每所有文章的标题一次性导出来放在titles.txt里
导出SQL代码,连接SSH终端,或类似宝塔面板里的终端:
mysql -uroot -p liuzhongwei -e "SELECT post_title from wp_posts INTO OUTFILE'/www/wwwroot/temp/titles.txt'"
liuzhongwei为服务器,注意后面的保存目录,根据实际情况,且temp目录需要有777权限。
把导出的titles.txt放在本地电脑,如C:\feng86目录下。
第二步,按装python,下载网址:https://www.python.org/downloads/windows/
推荐Python 3.9或Python 3.10都可以,
安装时注意勾选加入path选项,勾选 ✅ Add Python 3.9 to PATH(安装界面底部),安装最后一步别忘记了点:点击 Disable path length limit(如果出现)
最后打开windows的cmd输入:
python --version
pip --version
如果出现版本号 就是安装成功了,
接下来,安装依赖库
安装关键词提取需要的包(jieba、pymysql、tqdm):
在cmd里运行:
pip install jieba pymysql tqdm
第三步:
保存下面代码为:C:\feng86\extract_from_brackets.py
打开CMD,
cd C:\feng86
python extract_from_brackets.py
python代码:
import re
import csv
from collections import defaultdict
from tqdm import tqdm
INPUT_FILE = r'C:\feng86\titles.txt'
OUTPUT_FILE = r'C:\feng86\bracket_keywords.csv'
MIN_FREQUENCY = 2
# 中国省份
PROVINCES = set([
'北京','天津','上海','重庆','河北','山西','辽宁','吉林','黑龙江',
'江苏','浙江','安徽','福建','江西','山东','河南','湖北','湖南',
'广东','海南','四川','贵州','云南','陕西','甘肃','青海','台湾',
'内蒙古','广西','西藏','宁夏','新疆','香港','澳门'
])
# 过滤模式:共*卷、第*册、第*辑、上集、下集、pdf 等
FILTER_PATTERNS = [
r'共[一二三四五六七八九十百千万\d]+卷',
r'第[一二三四五六七八九十百千万\d]+(册|辑|集|部)',
r'上集', r'下集',
r'pdf'
]
compiled_patterns = [re.compile(p, re.IGNORECASE) for p in FILTER_PATTERNS]
def is_chinese_number(word):
chinese_digits = set('一二三四五六七八九十百千万零〇')
return all(char in chinese_digits for char in word) and len(word) >= 2
def extract_bracket_keywords(text):
patterns = [
r'【(.*?)】',
r'\[(.*?)\]',
r'《(.*?)》',
r'\((.*?)\)',
r'((.*?))'
]
results = []
for pattern in patterns:
results += re.findall(pattern, text)
return [r.strip() for r in results if r.strip()]
def is_valid_keyword(kw):
if len(kw) < 2:
return False
if kw in PROVINCES:
return False
if kw.isdigit():
return False
if is_chinese_number(kw):
return False
for pattern in compiled_patterns:
if pattern.fullmatch(kw):
return False
return True
def analyze_titles(lines):
freq = defaultdict(int)
examples = defaultdict(list)
for title in tqdm(lines):
keywords = extract_bracket_keywords(title)
for kw in keywords:
if is_valid_keyword(kw):
freq[kw] += 1
if len(examples[kw]) < 3:
examples[kw].append(title)
return freq, examples
def save_to_csv(freq, examples, file):
sorted_items = sorted(freq.items(), key=lambda x: x[1], reverse=True)
with open(file, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['关键词(最终过滤)', '出现次数', '示例标题'])
for word, count in sorted_items:
if count >= MIN_FREQUENCY:
writer.writerow([word, count, ' / '.join(examples[word])])
def main():
with open(INPUT_FILE, 'r', encoding='utf-8') as f:
lines = [line.strip() for line in f if line.strip()]
freq, examples = analyze_titles(lines)
save_to_csv(freq, examples, OUTPUT_FILE)
print(f'\n✅ 提取完成,共关键词:{len(freq)} 条,输出文件:{OUTPUT_FILE}')
if __name__ == '__main__':
main()
最后得到bracket_keywords.csv里的关键词,把里面的关键词复制出来,保存为keywords.txt
上传到网站目录的temp目录下,要有777权限哦。
再把下面的php代码复制保存为auto_batch_keywords.php也上传到网站目录下的temp目录里
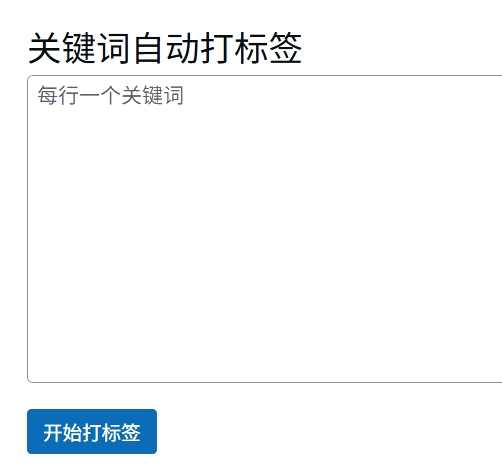
打开这个网页:https://www.liuzhongwei.com/temp/auto_batch_keywords.php
<?php
require_once('../wp-load.php');
$file = __DIR__ . '/keywords.txt';
$temp_file = __DIR__ . '/keywords_temp.txt';
$done_file = __DIR__ . '/keywords_done.txt';
$unmatched_file = __DIR__ . '/keywords_unmatched.txt';
$batch_size = 10;
$delay_ms = 15000;
// 重置请求检测
if (isset($_GET['reset']) && $_GET['reset'] == 1) {
if (file_exists($temp_file)) unlink($temp_file);
if (file_exists($done_file)) unlink($done_file);
if (file_exists($unmatched_file)) unlink($unmatched_file);
echo "<meta charset='UTF-8'><p>✅ 所有记录已清空,<a href='auto_batch_keywords.php'>点击这里重新开始</a></p>";
exit;
}
if (!file_exists($file)) {
exit("❌ 文件 keywords.txt 不存在");
}
if (!file_exists($temp_file)) {
copy($file, $temp_file);
}
$all_lines = file($file, FILE_IGNORE_NEW_LINES | FILE_SKIP_EMPTY_LINES);
$lines = file($temp_file, FILE_IGNORE_NEW_LINES | FILE_SKIP_EMPTY_LINES);
$total = count($all_lines);
$remaining = count($lines);
$processed = $total - $remaining;
$percent = $total > 0 ? round($processed / $total * 100, 2) : 0;
$batch = array_slice($lines, 0, $batch_size);
$leftover = array_slice($lines, $batch_size);
file_put_contents($temp_file, implode(PHP_EOL, $leftover));
echo "<meta charset='UTF-8'>";
echo "<h2>批量关键词打标签</h2>";
if ($processed > 0) {
echo "<p style='color:orange;'>⚠️ 正在从上次中断处恢复处理...</p>";
}
echo "<p>✅ 已处理:<strong>{$processed}</strong> / {$total}({$percent}%)</p>";
echo "<div style='width: 100%; background: #eee; border-radius: 5px; overflow: hidden; height: 20px; margin-bottom: 10px;'>
<div style='width: {$percent}%; background: #4caf50; height: 100%;'></div>
</div>";
echo "<ul>";
global $wpdb;
foreach ($batch as $keyword) {
$keyword = trim($keyword);
if ($keyword === '') continue;
$term = term_exists($keyword, 'post_tag');
if (!$term) {
$term = wp_insert_term($keyword, 'post_tag');
}
$tag_id = is_array($term) ? $term['term_id'] : $term;
$post_ids = $wpdb->get_col(
$wpdb->prepare(
"SELECT ID FROM {$wpdb->posts}
WHERE post_status = 'publish' AND post_type = 'post'
AND post_title LIKE %s",
'%' . $wpdb->esc_like($keyword) . '%'
)
);
if ($post_ids) {
$tagged_count = 0;
foreach ($post_ids as $pid) {
$current_tags = wp_get_post_tags($pid, ['fields' => 'names']);
if (!in_array($keyword, $current_tags)) {
wp_set_post_tags($pid, [$keyword], true);
$tagged_count++;
}
}
if ($tagged_count > 0) {
file_put_contents($done_file, $keyword . PHP_EOL, FILE_APPEND);
echo "<li>✅ 【$keyword】成功打到 $tagged_count 篇文章</li>";
} else {
echo "<li> 【$keyword】已存在于所有匹配文章中,无需重复打标签</li>";
}
} else {
file_put_contents($unmatched_file, $keyword . PHP_EOL, FILE_APPEND);
echo "<li>⚠️ 【$keyword】未匹配任何文章</li>";
}
}
echo "</ul>";
// 下载和操作按钮
echo "<div style='margin-top:20px;'>";
echo "<a href='keywords_done.txt' download style='display:inline-block;padding:8px 14px;background:#0073aa;color:#fff;border-radius:4px;margin-right:10px;text-decoration:none;'>⬇️ 下载已处理关键词</a>";
echo "<a href='keywords_unmatched.txt' download style='display:inline-block;padding:8px 14px;background:#d54e21;color:#fff;border-radius:4px;margin-right:10px;text-decoration:none;'> 下载未匹配关键词</a>";
echo "<a href='?reset=1' style='display:inline-block;padding:8px 14px;background:#777;color:#fff;border-radius:4px;text-decoration:none;'>️ 一键重置全部记录</a>";
echo "</div>";
if (count($leftover) > 0) {
echo "<script>
setTimeout(function() {
window.location.href = '" . $_SERVER['PHP_SELF'] . "';
}, {$delay_ms});
</script>";
echo "<p>⏳ {$delay_ms} 毫秒后自动跳转下一批...</p>";
echo "<button onclick=\"window.stop();\">⏸ 暂停</button>";
} else {
unlink($temp_file);
echo "<h3> 所有关键词处理完毕!</h3>";
}
?>
注意上面的代码里的
batch_size = 10; 一次性处理10个标签
delay_ms = 15000; 每15秒刷新一次。
这两个标签根据你服务器马力自行更改,别拉爆服务器就行。
全部完了,希望你看得懂。